

动手学微服务(一)实战MySQL读写分离和分库分表
《动手学微服务》系列文章将专注微服务中的常见思想、常用技术和常见架构。本系列的特点是不仅在理论上对微服务的知识进行梳理,还会有一系列的动手实践,不仅在平时学习会有帮助,也有助于面试。本人也是微服务的小学徒,为了巩固所学而创建此专栏,欢迎大家持续关注。
为何需要读写分离?从一个业务场景说起
我们以用户中台这个服务场景来说明为何需要读写分离的架构。
一个公司可能有多个产品,多个产品的用户数据一般是相同的。在传统的用户体系中,每个项目会对应一套用户系统,这不仅在技术上维护困难,代码冗余,在业务上没能将业务数据很好地利用起来做一些挖掘和分析。
用户微服务(用时髦点的话来说就是用户中台)就是在这种背景下出现的。它具有如下特点:
- 统一用户数据管理
- 方便不同业务线接入
- 高性能、高并发、高可用
🥲废话了这么多,这跟读写分离有什么关系?
当然有关系,在用户中台的架构演变过程中,最早是使用MySQL单机 + Redis单机这种方案,然而这种方案不可避免的会存在这样两个问题:
- MySQL成为性能瓶颈
- 存在单点风险
因此,后面就在此基础上进一步的演进,推出了MySQL读写分离架构、Redis哨兵架构、Redis分片集群架构等。而今天我们要介绍的就是MySQL的读写分离架构,简易架构图如下所示。
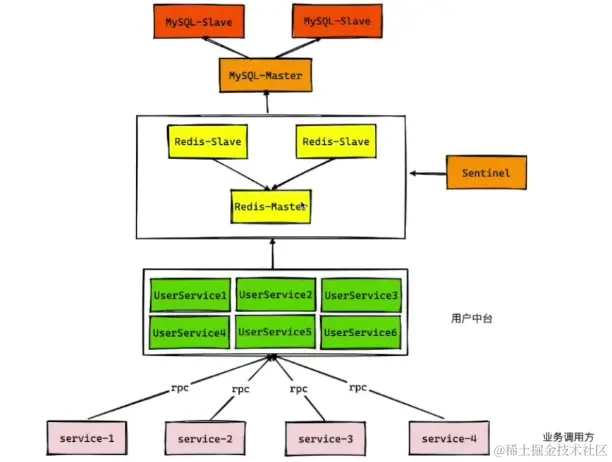
我们平时在做项目的时候,要多从架构上想一想思考点,面试的时候才能游刃有余。在这个场景我们可以总结出如下的一些架构思考点:
- 高并发下如何处理MySQL的读压力问题?
- 主从节点的机器配置该如何选择?主节点的配置高于从节点一定好吗?
- 如何解决主从复制中的主从延迟问题?
- 如何进行分片的选择?
- ...
读写分离的那些事儿
什么是读写分离
简单来说,读写分离用于将对数据库的读写操作分散到不同的机器节点上,从而大幅提高机器的读性能。
我们一般通过搭建MySQL主从架构实现读写分离,其中主节点主要用于写操作,从节点主要是读操作。这种设计符合实
际业务中读多写少的特点。
读写分离的实现
读写分离的一般实现步骤如下:
- 第一,主从数据库搭建部署。
- 第二,基于binlog实现主从复制。
- 第三,在业务层将写请求分配给主库,读请求分配给读库。
常见的实现方案有:
- 增加代理层。在应用层和DB层之间添加一个代理层,负责分离读写请求和路由。
- 例子:MySQL Router、Atlas
- 使用第三方组件。互联网公司用的最多。。
- 例子:ShardingJDBC
聊一聊主从复制的原理
MySQL的主从复制依赖于binlog,binlog即二进制日志文件,主要记录了MySQL中所有的DDL和DML语句。主库通过binlog将数据同步给从库,从库再进行恢复。
主从复制的大致步骤如下:
- 主库将数据库变化的语句写入binlog。
- 从库连接🔗主库,创建IO请求向主库请求更新的binlog。
- 主库创建
binlog dump线程发送binlog。 - 从库中IO线程负责将接收到的
binlog写入到relay log,SQL线程负责将relay log同步到本地。
读写分离的挑战
软件开发中没有银弹。引入读写分离架构虽然在一定程度上提高了MySQL的读性能,但是也存在着一些挑战,最典型的就是主从延迟问题了。
这里也挖个坑😊:如何解决主从延迟将在《动手学微服务》系列文章的最近更新哦。
分库分表的那些事儿
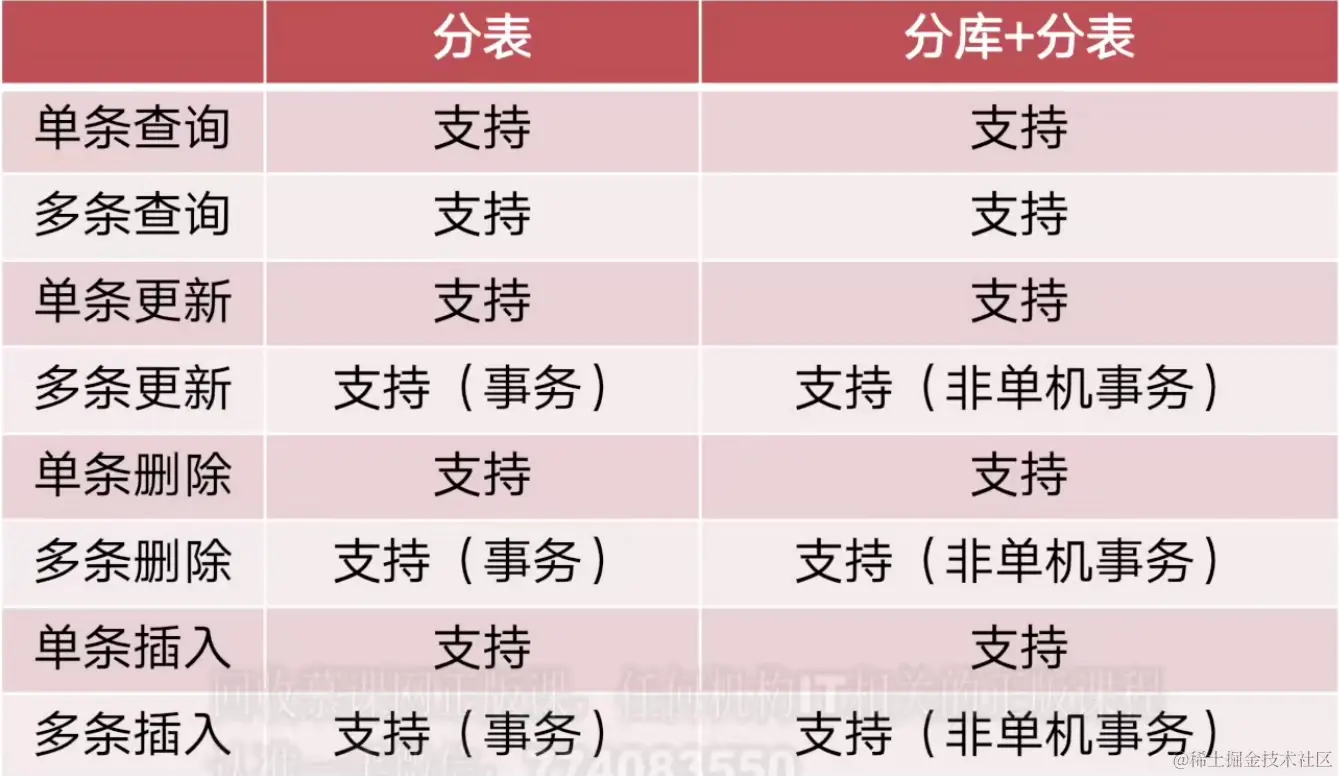
读写分离解决的是MySQL的读请求太多的问题,分库分表解决的是数据存储压力的问题。
什么是分库分表
分库:将数据分散到不同的数据库中。一般有两种分库方式:
- 垂直分库:原来只有一个数据库,现在按照业务划分成不同数据库。
- 例如:将用户表和订单表分别独立为用户数据库和订单数据库。
- 水平分库:原来只有一个数据库,里面有一张表数据量特别大,现在按照一定规则将它分配到不同数据库中。
- 例如:将一个大的订单表拆分成两张,分别放到不同的数据库中。
分表:对单表进行数据拆分。
- 垂直分表:数据列的拆分,把一张列比较多的表拆分为多张表。
- 例如:把订单表拆分为单头表和订单详情表。
- 水平分表:一张表的数据量太大,拆成多张,解决单表数据量过大的问题。
- PS:为了提升性能,我们还会将拆分后的多张表放到不同数据库中。
- 所以说,水平分库和水平分表常常一起出现。
分片算法
分片算法解决水平分片后数据的存放位置问题。
常见的分片算法有:
- Hash分片:根据Hash值确定数据分配到哪个表。
- 适合:随机读写的场景。
- 不适合:经常需要范围查询;数据库表经常需要动态伸缩
- 范围分片:按照某个字段的范围进行分片。
- 适合:经常需要范围查找。
- 不适合:随机读写。因为数据没分散,容易出现热点数据问题。
- 一致性Hash分片:将存储节点和数据都映射到一个Hash环上,增加和移除节点只影响相邻节点。
- 解决了Hash分片对动态伸缩不友好的问题。
- 引入虚拟节点可以防止所有请求都打到同一个节点的问题。
- 一篇不错的博客:9.4 什么是一致性哈希? | 小林coding (xiaolincoding.com)
- 地理位置分片。
- 融合算法分片:灵活组合不同。
分库分表的挑战
选择一个技术必须基于实际的业务场景,不是说今天学了微服务以后就一定要分库分表。引入分库分表也会带来一些成本和挑战。
- 无法使用join:数据分散到不同库中。对于需要使用join操作的地方,可以通过多次查询业务层实现。
- 分布式事务:多数据库的话就传统的事务就不适用了。
- 分布式主键:多数据库的话就无法保证ID唯一了,需要引入分布式ID,本专栏以后也会讲有这部分内容。
- 聚合操作困难:group by 和 order by等操作困难,需要通过业务层和中间件来实现。
分库分表的中间件
- Sharding Proxy
- Sharding JDBC
- Sharding Sidecar
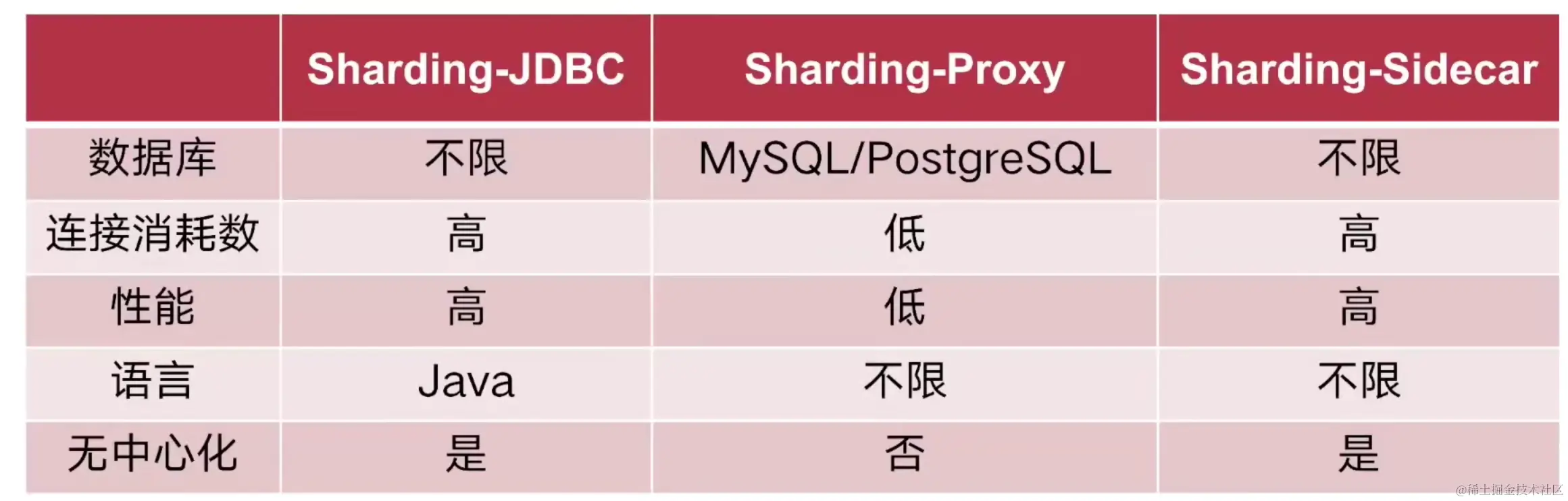
这里也挖个坑😊:如何ShardingJDBC的使用将在《动手学微服务》下一篇文章更新哦。
动手学
在这个部分我们以设计用户中台项目的用户表为例,实践一些上面说过的读写分离和分库分表。
实战表设计;冷热分离思想
我们的动手学从设计一张用户表开始,数据库的设计其实也能够体现我们的架构思考。
👿 用户表设计还用你教我?
一个用户表一般具有下面的字段:userFlag、city、nickname、avatar、updateTime、lastActiveTime、userId、phone、sex、createTime。
但是仅仅考虑到这一层还不够,我们还可以更加深入地思考,尝试一下动静分离的设计思想,也即将冷热字段进行分离。我们根据读写的场景对字段进行分类:
- 读多写少:userId、nickname,avatar、sex、phone
- 读多写多:lastActiveTime,userFlag
分析完后因此我们将userFlag可以单独放一张表,这里只创建读多写少的数据库表。
实战分表创建:通过存储过程创建分表
假设我们有1亿条用户数据,分100张,每张100W数据,走索引的话效率还是很高的。
我们创建一个存储过程来创建表,这里我稍微解释一下:
- table_body:建表的SQL片段中的字段信息。
- table_name:形成00、01、02...99这100张表。
- sql_text:通过concat拼接形成的最终执行的建表SQL。
DELIMITER ;;
CREATE DEFINER=`root`@`%` PROCEDURE `create_t_user_100`()
BEGIN
DECLARE i INT;
DECLARE table_name VARCHAR(30);
DECLARE table_pre VARCHAR(30);
DECLARE sql_text VARCHAR(3000);
DECLARE table_body VARCHAR(2000);
SET i=0;
SET table_name='';
SET sql_text='';
SET table_body = '(
user_id bigint NOT NULL DEFAULT -1 COMMENT \'用户id\',
nick_name varchar(35) DEFAULT NULL COMMENT \'昵称\',
avatar varchar(255) DEFAULT NULL COMMENT \'头像\',
true_name varchar(20) DEFAULT NULL COMMENT \'真实姓名\',
sex tinyint(1) DEFAULT NULL COMMENT \'性别 0男,1女\',
born_date datetime DEFAULT NULL COMMENT \'出生时间\',
work_city int(9) DEFAULT NULL COMMENT \'工作地\',
born_city int(9) DEFAULT NULL COMMENT \'出生地\',
create_time datetime DEFAULT CURRENT_TIMESTAMP,
update_time datetime DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (user_id)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb3 COLLATE=utf8_bin;';
WHILE i<100 DO
IF i<10 THEN
SET table_name = CONCAT('t_user_0',i);
ELSE
SET table_name = CONCAT('t_user_',i);
END IF;
SET sql_text=CONCAT('CREATE TABLE ',table_name, table_body);
SELECT sql_text;
SET @sql_text=sql_text;
PREPARE stmt FROM @sql_text;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
SET i=i+1;
END WHILE;
END;;
DELIMITER ;
最后别忘记调用:call create_t_user_100();
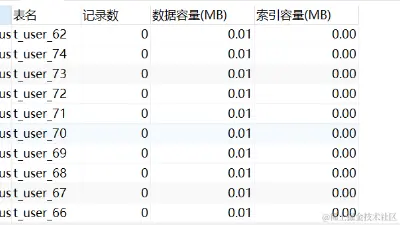
我们可以通过下面语句查询数据库的占用空间:
select
table_schema as '数据库',
table_name as '表名',
table_rows as '记录数',
TRUNCATE(data_length/1024/1024,2) as '数据容量(MB)',
TRUNCATE(index_length/1024/1024,2) as '索引容量(MB)'
from information_schema.`TABLES`
where table_schema = 'test_user'
order by data_length desc, index_length desc;
当然,在这里我们仅仅只是做了数据层面的分表,还需要业务层面引入ShardingJDBC来配合,ShardingJDBC将在下一篇文章中讲解。
实战MySQL主从架构搭建:基于Docker
下面我们实战一下通过Docker来搭建MySQL的主从架构。
数据卷挂载
首先创建挂载文件夹,主节点和从节点都要创建。
[root@VM-4-2-centos ~]# mkdir -p /usr/local/mysql/master1/conf
[root@VM-4-2-centos ~]# mkdir -p /usr/local/mysql/master1/data
[root@VM-4-2-centos ~]# mkdir -p /usr/local/mysql/slave1/conf
[root@VM-4-2-centos ~]# mkdir -p /usr/local/mysql/slave1/data
进入主数据库目录:
cd /usr/local/mysql/master1/data
初始化主数据库的配置:新建 my.cnf,主要做了下面几件事:
- 配置数据卷目录
- 主从服务的ID配置。
- 启动binlog
- 设置binlog的格式
[mysqld]
datadir = /usr/local/mysql/master1/data
character-set-server = utf8
lower-case-table-names = 1
# 主从复制-主机配置
# 主服务器唯一ID
server-id = 1
# 启用二进制日志
log-bin = mysql-bin
# bin log格式
binlog_format=STATEMENT
修改从数据库的配置:
cd /usr/local/mysql/slave1/conf
新建 my.cnf,这里设置的是relay-log
[mysqld]
datadir = /usr/local/mysql/slave1/data
character-set-server=utf8
lower-case-table-names=1
# 从节点配置
server-id=2
# 启动中继日志
relay-log=mysql-relay
修改文件权限:
chmod -R 777 /usr/local/mysql
创建容器
接下来拉取MySQL的镜像:
docker pull mysql:8.0
运行主节点容器:
docker run --name=mysql-master-1 \
--privileged=true \
-p 8808:3306 \
-v /usr/local/mysql/master1/data/:/var/lib/mysql \
-v /usr/local/mysql/master1/conf/my.cnf:/etc/mysql/my.cnf \
-v /usr/local/mysql/master1/mysql-files/:/var/lib/mysql-files/ \
-e MYSQL_ROOT_PASSWORD=你的密码 \
-d mysql:8.0 \
--lower_case_table_names=1
跑从节点的容器:
docker run --name=mysql-slave-1 --privileged=true \
-p 8809:3306 \
-v /usr/local/mysql/slave1/data/:/var/lib/mysql \
-v /usr/local/mysql/slave1/conf/my.cnf:/etc/mysql/my.cnf \
-v /usr/local/mysql/slave1/mysql-files/:/var/lib/mysql-files/ \
-e MYSQL_ROOT_PASSWORD=你的密码 \
-d mysql:8.0 \
--lower_case_table_names=1
到这里我们就已经搭建好MySQL的主从架构了,现在我们需要设置一个账号来授权主从同步。
创建用于主从同步的账号
我们先用Navicat等工具分别连上主节点和从节点。
主节点:创建账号,授权。
# 创建账户,设置主从同步账户名
create user 'test-slave'@'%' IDENTIFIED WITH mysql_native_password by '你的密码';
# 授权
grant replication slave on *.* to 'test-slave'@'%';
# 刷新权限
flush PRIVILEGES;
可以通过下面命令查询主从节点的状态:
# 查询server_id
show VARIABLES like 'server_id';
# 查询master状态
show master status;
# 查询binlog有哪些
show binlog events;
# 重置master下的binlog
reset master;
可以看到主节点的master状态,设置从节点需要用。

设置从节点的配置:
show VARIABLES like 'server_id';
# 可以临时指定server_id,重启后失效,这里为了防止和主节点id相同
set GLOBAL server_id = 2;
# 如果之前同步过,需要重置
stop slave;
reset slave;
# 设置主数据库
change master to master_host='主机',master_port=端口,master_user='test-slave',master_password='刚才设置的密码',master_log_file='binlog.000001',master_log_pos=157;
# 开始同步
start slave;
# 查询slave状态
show slave status;
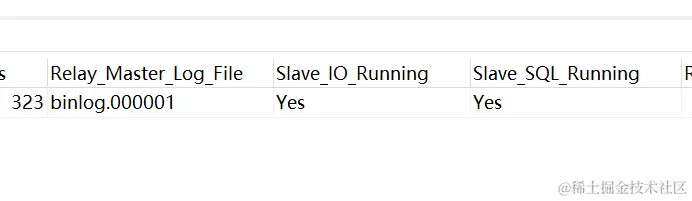
如果看到Slave_IO_Running和Slave_SQL_Running两个都是YES,表示成功了:
测试
在主节点新建表。
create database test_user character set utf8mb3 collate=utf8_bin
如果发现从节点也可以看到这张表,恭喜你搭建成功!
总结
本文介绍了MySQL的读写分离和分库分表的基本理论和相关实践,动手实操了根据冷热分离思想进行表设计、基于存储过程创建分表、基于Docker搭建MySQL的主从节点这三个内容。
后面的《动手学微服务》系列文章将更新ShardingJDBC的实践、利用RocketMQ解决主从延迟的最终一致性问题,欢迎持续关注👏。
- 感谢你赐予我前进的力量
-
 微信
微信 - 支付宝