

DL数学原理:香农熵、交叉熵、KL散度
DeepSeek-R1最近刷屏全网,与之相随的是有关大模型强化学习的学习热潮。在大模型的强化学习中,有一个概念经常被提及——KL散度。正好最近复习了一下香农熵、交叉熵、KL散度的概念,将他们串在一起将更有利于理解KL散度。
信息量:小概率事件的信息量更大。用-log可以表示这层关系。

熵(香农熵):针对概率分布来说,包含的平均信息量。描述概率分布的不确定性。数学表达式就是对信息量求个期望。
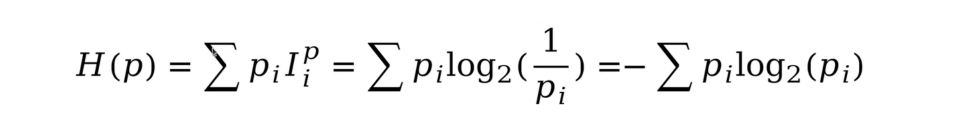
对于一个概率分布,如果概率密度更加均匀,那么随机变量的不确定性就更高,就会产生更大的熵。相反,如果概率密度函数更加聚拢,那么随机变量就会更加确定,熵就会更小。
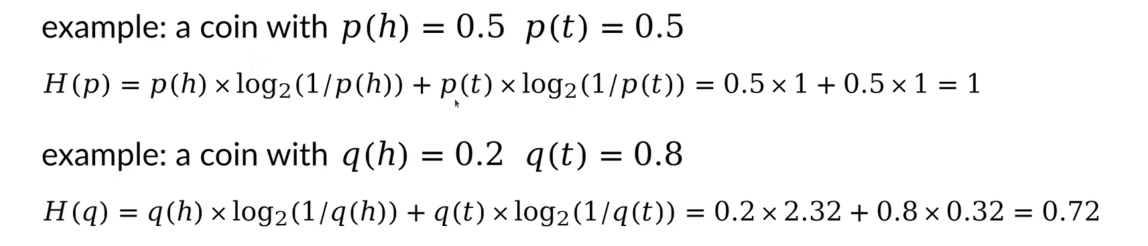
交叉熵:给定一个估计出来的概率分布q,计算对真实的概率分布p的平均信息量的估计就叫做交叉熵。
对于数学表达式,我们仅需要在计算熵的时候将信息量替换为估计的信息量,就得到最终表达式。

从下面例子观察到,交叉熵似乎都是比原分布的香农熵要大,而且似乎分布越接近,交叉熵就越接近。
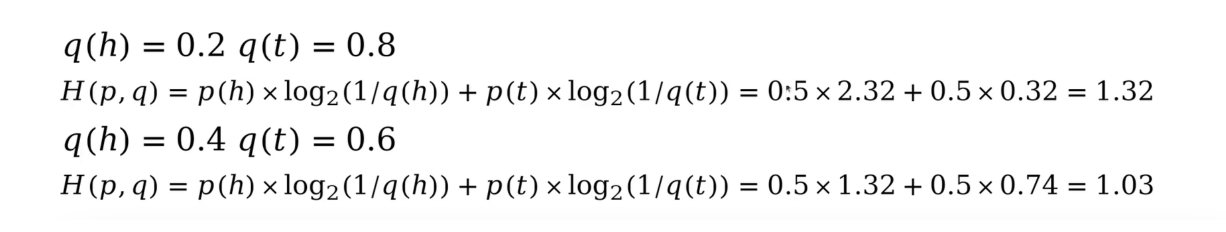
KL散度:用于量化衡量两个概率分布的区别。数学定义就是交叉熵减去原分布的熵。
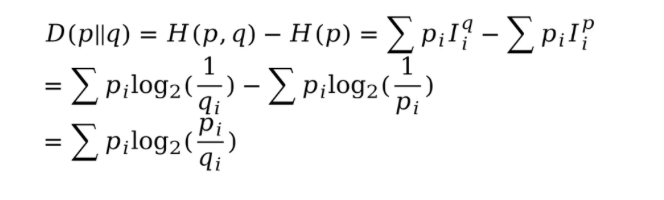
性质:
- KL散度永远大于0。只有当p和q两个概率分布完全一致时,KL散度等于0。
- pq交换后KL散度是不一致的,所以KL散度不是距离的衡量。
最小化KL散度等价于最小化交叉熵,所以才有了交叉熵用于损失函数。
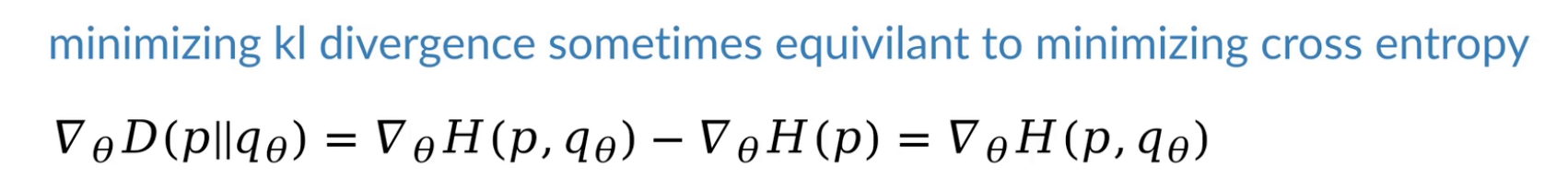
另一个角度理解KL散度:
基于概率分布P采样随机数序列,分别求序列在两个分布下的概率,再比较两个概率, 如果结果相近就说明分布相近,如果结果相差比较远就证明分布相差比较大。

- 感谢你赐予我前进的力量
-
 微信
微信 - 支付宝
赞赏者名单
因为你们的支持让我意识到写文章的价值🙏
本文是原创文章,采用 CC BY-NC-ND 4.0 协议,完整转载请注明来自 AjaxZhan
评论
匿名评论
隐私政策
你无需删除空行,直接评论以获取最佳展示效果