

如何构建高质量代码相关基准数据集
最近读了一篇聚焦“如何构建代码相关基准数据集”的论文,对研究人员来说,绝对是一份实用指南,特此分享。
参考文章:How Should I Build A Benchmark? Revisiting Code-Related Benchmarks For LLMs
作者:香港科技大学博士Jialun CAO
研究概述
作者分析了10年内274个基准数据集,发现许多基准在仍然样本重复、错误的参考代码/测试/提示、未删除的敏感信息等问题,因此提出了55条标准清单用于帮助研究人员构建高质量、高可靠、可复现的代码相关基准数据集。
评测数据集的构建生命周期分为五个阶段,可以用下图概括:
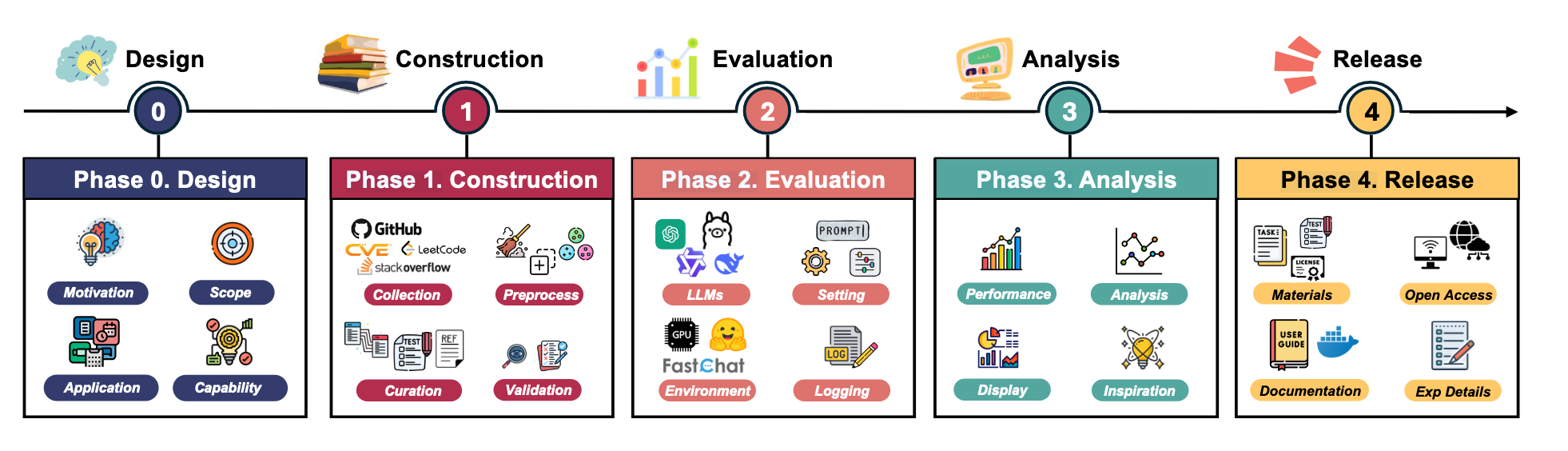
二、基准开发的生命周期
(一)阶段一:设计阶段
- 关键:识别目标应用场景的动机、范围和所需能力。
- 指南:
- 明确构建的基准是否可以填补相关研究的空白:确保基准的必要性,避免重复无效工作。
- 明确基准的预期范围:清晰界定要测试的能力,如意图理解、代码生成等,保证评估精准。研究发现部分基准缺乏范围定义,部分基准的例子超出目标评估能力。
- 明确基准的预期应用场景:例如编码助手、自动测试等,以便针对性地设计基准。
- 明确基准期望评估的大模型的能力(如理解、推理、计算等)和领域知识(如 OOP、内存管理、错误定位、进程调度等) ,使评估更全面。
- 现有基准的问题:在能力范围和编程语言方面失衡,更偏向代码生成和 Python 语言。约 36.1% 的基准是代码生成,9.8% 代码修复,9.1% 漏洞检测、9.1% 代码总结,8% 的 Text2SQL,其他还包括代码检索、代码推理、代码翻译、测试生成、代码优化、代码补全、代码分类、Api 推荐 。
(二)阶段二:构建阶段
- 关键:包括数据收集、数据预处理(过滤、去重、降噪)、数据整理和数据验证。
- 指南:
- 数据源:确保数据源具备可追溯性,对其进行质量筛选(如高 star 项目),且具有代表性(选择能匹配任务的开源社区)。
- 数据预处理和数据整理:考虑数据在收集阶段的污染问题(如数据上传时间,是否包含在大模型训练数据中);思考是否需要数据采样,若需要,保证采样大小科学(置信区间、错误边界、采样比例),采样过程严谨(随机采样、分层采样);确保数据都落在测试目标范围内,能覆盖研究的模型能力、领域知识和应用场景;保证每个样本都有标准答案,代码可编译和可执行;检查并降低数据噪声概率,检查并去除重复数据,清理敏感数据。
- 数据验证:通过手工 review、使用大模型 review;设计合适的验证方法(额外的匹配或者设计测试用例);设计合适的评估指标并考虑其充分性,还可考虑额外评估指标(例如可读性、有效性、安全性)。
- 现有基准的问题:62% 未考虑去重,80% 未考虑数据污染处理,70% 未经过质量保证检查。
(三)阶段三:验证阶段
- 关键:选择代表性的模型、配置一致性的提示词和参数、选择合适实验环节、记录日志保证可复现。
- 指南:
- 模型选择:确保模型充足且有代表性(最近发布 / 经典模型、小 / 大模型、开源 / 闭源)。
- 参数配置:提示词需经过验证,尝试不同提示词及不同提示词策略(研究表明,不同 prompt 在代码翻译任务中的性能差距可达 40%)。
- 环境:明确 gpu、存储大小、操作系统、框架和库等环境因素。
- 可复现:重复多次实验减少随机性影响,考虑不同的随机策略(如不同的温度参数),记录实验细节(参数设计、运行时间、输入输出对等)。
(四)阶段四:分析阶段
- 关键:识别出色 / 不佳模型、可视化实验结果、得到更深刻的洞见(如模型相关性、基准相关性、上下游任务性能)。
- 指南:
- 难度:判断基准是否太难或者太容易。
- 可区分度:看是否能区分出不同模型的优缺点。
- 稳定性:观察多次实验结果差距是否很大。
- 分析数据和得分的相关性。
- 对比:与大模型在其他基准的得分做对比。
- 可视化数据并清晰展示(如大小、颜色),避免绘制难以理解的图。
- 解释实验结果:从不同角度观察联系(如模型大小、上下文大小),得出有启发性的结论。
(五)阶段五:发布阶段
- 关键:准确整理相关材料、提供文档和指导、公开实验细节。
- 指南:
- 选择合适的开源协议:确保不包含敏感信息和有毒信息(如不好的评论)。
- 保证数据集、测试案例和参考数据、提示词、环境细节、实验细节的可访问性和开源性。
- 设计 readme:提供脚本能让用户高效使用数据集。
结语
作为一名构建数据集的初学者,这篇文章为我提供了清晰的思路与方法,从基准开发的各个阶段详细阐述,帮助我系统地掌握了构建数据集的要点。而对于经验丰富的学者而言,文章中提出的问题与 55 条标准清单,无疑是一份难得的自查指南,能帮助大家审视过往研究中的不足,进一步提升研究质量。
在未来研读数据集相关文章时,我认为可以结合作者给出的 checklist来帮助我们更高效地评估现有数据集的优劣,在自己构建数据集时,也能更有针对性地规避问题,确保工作的严谨性与可靠性。
- 感谢你赐予我前进的力量
-
 微信
微信 - 支付宝
赞赏者名单
因为你们的支持让我意识到写文章的价值🙏
本文是原创文章,采用 CC BY-NC-ND 4.0 协议,完整转载请注明来自 AjaxZhan
评论
匿名评论
隐私政策
你无需删除空行,直接评论以获取最佳展示效果