

爬虫攻防:一次js动态cookie的反爬虫解决经历
本文记录一次js动态生成cookie的反爬虫的解决过程。这个反爬卡住了我整整2天,在多次尝试之后终于成功爬取,遂将过程中踩的坑和经验记录一下。
⚠️声明:本次爬虫仅仅是爬取网站上【公开】的【新闻公告】数据,其目的仅仅是为了制作一个自动订阅工具,无盈利目的和其他目的。同时,rss订阅器的请求频率非常低,不会给服务器造成压力。
需求分析与反爬策略分析
事情是这样的,我想要爬取某校官网的新闻,制定一个RSS订阅源,原因也在前面的文章说过,每次想要获取最新资讯我都得一个一个网站点进去查看,这也太不方便了,如果能够将所有网站都集成到一个rss阅读器里面,每日我就只需要点进去rss阅读器看看有无最新消息即可。
然而,某学校大部分学院的新闻公告界面都没有反爬策略,唯独某学院和两个官网有反爬虫策略,我当时采用了很多种方案都行不通。这就让我很苦恼了,如果我还需要一个一个点进去这两个网站,那我的rss岂不是就意义不大了。
所以我决定好好分析一下他的反爬策略,看看能不能反反爬虫。经过我的抓包分析,我发现这些网站的反爬虫策略都是一样的,具体表现为:
- 浏览器第一次发送http请求给服务器,服务器返回一段加密过后的js,状态码202,并返回一个cookie。
- 浏览器执行js脚本,计算出第二个cookie。
- 浏览器第二次携带2个cookie发送请求给服务器,服务器返回正常数据。如果没有带上cookie或者cookie错了,就不会返回信息。
这是一种典型的反爬虫策略:浏览器一段JS生成一个(或多个)cookie再带着这个cookie做二次请求。服务器那边收到这个cookie就认为你的访问是通过浏览器过来的合法访问。更多js反爬虫可见这个帖子:反爬虫的四种常见方式-JS逆向方法论
这里的关键在于,服务器执行了一段加密后的js脚本,我们无法从js脚本里面得知是在哪个地方设置的cookie,更无法得知其算法。那怎么办呢?
尝试过的解决方案
分析完原因之后,我们就可以开始思考解决方案了。这里记录我尝试过的几种解决策略,算是把踩过的坑分享一下。
策略1:js逆向
第一个策略我采用的是js逆向。然而服务器返回的js是混淆和加密过的,我压根读不懂呀,直接搜cookie也搜不出来,于是我必须借助工具帮我查找cookie更改的位置,上GitHub一搜,居然真有人做了这个插件。
首先给浏览器装一个油猴扩展插件,并在使用油猴扩展商店下载js脚本:JS Cookie Monitor/Debug Hook,它可以在控制台打印cookie的增删改变化情况以及定位到原始Cookie的位置。
插件GitHub地址:JS Cookie Monitor
如图所示,脚本的Cookie修改监控功能,能够让我们更宏观的角度分析页面上的Cookie。
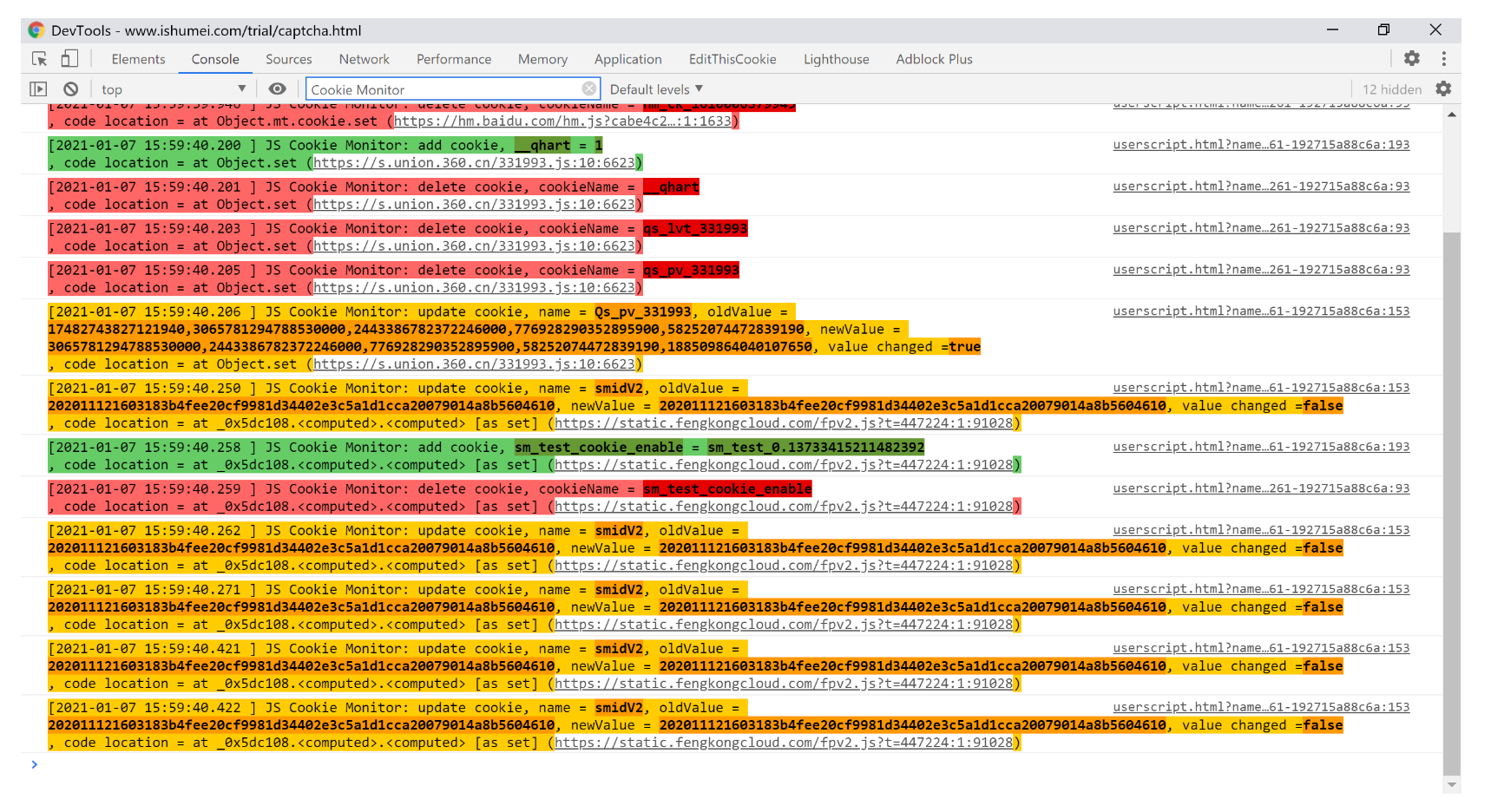
不过最后结果也失败了,原因是就算有插件帮我看cookie,虽然是简化的一些找源代码的流程,但确实还是有点复杂,放弃了。(这个网站Cookie居然还会增删改好多次,要想纯js逆向模拟出加密后的cookie有点太复杂了)
策略2:Puppeteer
Puppeteer是一个javascript的库,可以模拟Chrome浏览器进行爬虫。想法也很简单,与其自己js逆向其算法,不如直接让浏览器执行这段js脚本,那cookie不就出来了。
Puppeteer文档:puppeteer-api-zh_CN
想法很简单,但实际上对方服务器会检测是否使用了自动化工具。Puppeteer一下子就被检测出来了,服务器直接返回了400 bad request。
当然我又上网找了一些策略来防检测,但是就算我把各种策略都用上了,还是过不了服务器的检测。中间我也尝试了一个puppeteer中的反检测插件puppeteer-extra-plugin-stealth,也是行不通。这条路算是走不通啦。
策略3:selenium
直接使用js来爬虫我是没什么招了,我打算借用Python中更强大的selenium库。这个库的本质也是开模拟浏览器来进行爬虫,而且生态十分成熟。好家伙,直接换语言了。
尽管RssHub原生是使用javascript进行编写,如果我使用Python的话肯定不太兼容,也不是最优雅的解决办法。但这时候也没办法啦,我完全可以启动一个FastApi给js端调用,也能达到目的。
这里有一个小知识点是这种模拟浏览器的爬虫方式可以分为有头和无头模式。有头模式就是启动爬虫的时候会打开一个chrome,你能看到这个网站内的东西。无头就是不会打开chrome,所有请求都是在后台运行的。并且使用无头模式很容易能够被检测出来。
果不其然,当我在本机使用selenium的时候,也是会被服务器检测到并发送400 bad request。我也搜了一些参数可以防止检测,但对于这个服务器来讲似乎都不起作用,有头模式和无头模式都行不通。
策略4:undetected_chromedriver
搜了一下后发现有uc(undetected_chromedriver)这个好东西,他对selenium做了优化,可以对抗服务器的检测。
整个代码也非常简单:
import undetected_chromedriver as uc
driver = uc.Chrome(headless=True,use_subprocess=False)
driver.get('你的url')
driver.save_screenshot('nowsecure.png')
简单试了一下,居然成功了!然而, 不要高兴太早,这仅仅是有头模式。不要忘记Linux下是没有可视化界面的,这也就意味着如果要将爬虫部署到服务器上就只能采用无头模式。
我尝试使用一下无头模式,又失败了,服务器还是检测出来无头模式。也难怪:如果这么无头模式仅仅让uc这么简单几行代码就实现反检测了,那也太不现实了。
不过,Linux似乎也可以实现xvfb来模拟可视化界面(Xvfb是流行的虚拟现实库,可以使很多需要图形界面的程序虚拟运行),这个方案我一开始尝试后失败了,所以就没有深究,不过回头看感觉不一定是这里的问题,可能是Linux中Chrome的问题,所以这个方法或许可行,感兴趣的读者可以尝试一下。
回过头来,如果只能在有头模式下运行,本质上还是没有解决问题。所以还需要看看有没有其他解决方案。
最终采用的解决方案
正当我一筹莫展的时候,我无意中在GitHub Issue(undetected-chromedriver/issues/2083)中搜到seleniumbase这个库,看了一下。这个库其实不是为爬虫设计的,主要是为自动化设计的,但是它也集成了uc,所以可以试试。
这个库的官方文档如下:seleniumbase.io,想要使用的话,代码也很简单:
def run_crawler(url):
with SB(uc=True,test=True, headless=True, ad_block=True) as sb:
sb.activate_cdp_mode(url)
sb.open(url)
sb.sleep(5) # 等待页面加载
js_script = """
let items = [];
document.querySelectorAll('#bg2 div main ul li').forEach(li => {
let time = li.querySelector('time')?.innerText || "未知日期";
let a = li.querySelector('a');
let title = a?.getAttribute('title') || "未知标题";
let href = a?.getAttribute('href') || "";
items.push({title, href, time});
});
return items;
"""
rss_items = sb.execute_script(js_script)
for item in rss_items:
item["link"] = convert_to_absolute_url(item["href"],url)
del item["href"]
rss_feed = {
"channel": {
"title": "通知公告",
"link": url,
"description": "公告信息",
"items": rss_items,
}
}
print(rss_items)
return rss_feed
编写上述代码运行后,我惊讶的发现在我的本机能够启动了,尽管是在无头模式,也不会被检测到。真是神奇,没想到一个做自动化测试的软件可以被用来完美解决反爬虫的问题。
这里有一个小技巧是,我们execute_script来运行javascript从而获取数据,而不是各种get、find方法。因为这个库是为了测试而做的,似乎没有那种直接通过element拿到元素的很方便的api,所以使用js来获取数据算是一个不错的方法。
小插曲:本机能跑,Linux机器跑不了?
正当我开心地将程序跑到Linux服务器上的时候,我发现Linux机器上一直报出:selenium.common.exceptions.sessionnotcreatedexception: message: session not created: cannot connect to chrome at 127.0.0.1:9222的错误,我上网搜了很久也没找到解决方案。
最终在这个GitHub Issue下面找到了解决方案:Github Issue:SeleniumBase/discussions/2931,原来在uc模式中,必须使用常规 chrome,而不是 chromium。chrome的二进制版本将被称为 google-chrome 或 google-chrome-stable,而我之前服务器上安装的只有chromium。
使用下面命令安装完Chrome就完美解决啦!
wget https://dl.google.com/linux/direct/google-chrome-stable_current_amd64.deb
sudo apt install ./google-chrome-stable_current_amd64.deb
小结
总结下来,为了做一个rss订阅器,还是花费了不少的功夫的。本来是为了图方便,但是在编码过程和debug过程也付出了大量的时间,尤其是后者,在处理反爬虫策略的时候花费了我大量时间查询资料和调试程序,果然懒惰也是需要代价的哈哈哈。
这一趟下来我发觉,爬虫并不只是简单地使用request库发送http请求,它涉及到的攻防知识非常多,我仅仅是爬取了一个简单的公开信息网站都需要研究这么多,其他的网站就更不必说了。好在我有过一些前后端的开发经验,研究起来会更不容易碰壁一些。
爬虫领域中攻和防在互相厮杀中结下孽缘却又相互提升着彼此。爬虫和网站是一对冤家,相克相生。爬虫知道了反爬策略就可以做成响应的反-反爬策略;网站知道了爬虫的反-反爬策略就可以做一个“反-反-反爬”策略……道高一尺魔高一丈,两者的斗争也不会结束。
真是一场酣畅淋漓的攻防游戏。
- 感谢你赐予我前进的力量
-
 微信
微信 - 支付宝